LangChain 实现 RAG
Written: 2026.061. LangChain RAG 组件与流程
1.1 LangChain组件
LangChain 框架提供了丰富的组件帮助我们搭建 RAG 应用,下面是关于这些核心组件的介绍:1.2 LangChain 实现流程
在RAG准备阶段,LangChain通过文档加载器对各种格式的文档进行加载,转换为LangChain中的文档对象,之后对文档对象进行分割,根据分割规则,分割成文档片段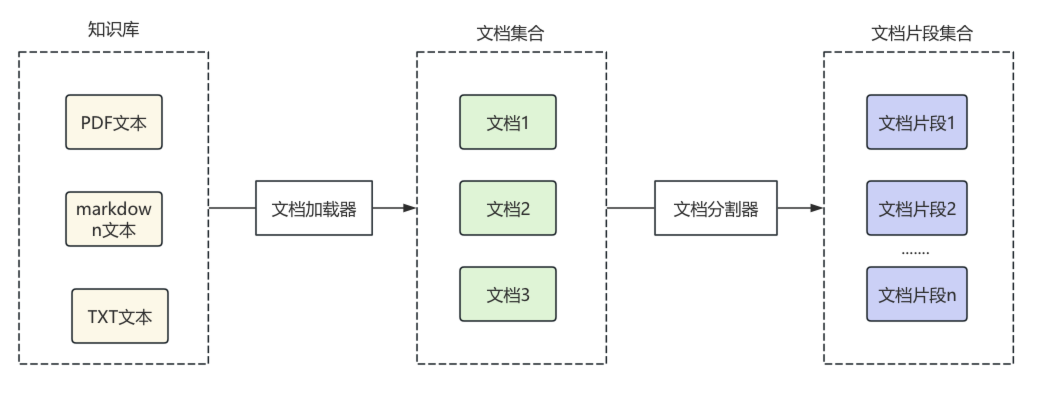
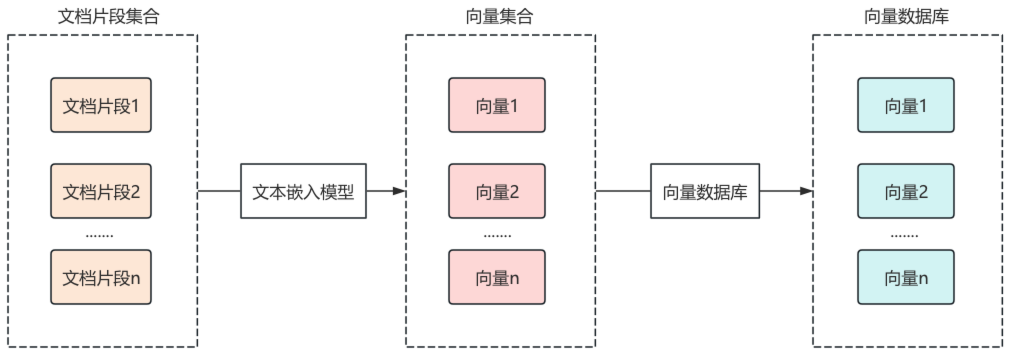
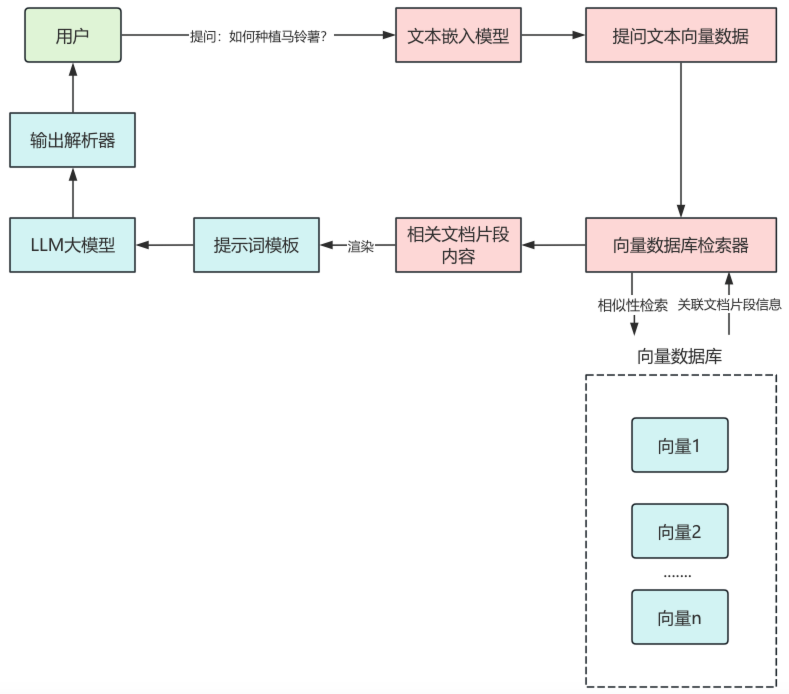
2. 文档加载器
在LangChain中,文档加载器用于将各种格式的文档转换为Document对象,LangChain提供了大量的文档加载器,支持从各种来源加载文档,如文件、数据源、URL等
2.1 LangChain 文档加载器
每一个文档加载器都有自己特定的参数和方法,但它们有一个统一的
load()方法来完成文档的加载,load()方法会返回一个Document类的对象列表,因为这些文档加载器都继承自BaseLoader基类,它们的继承关系如下:
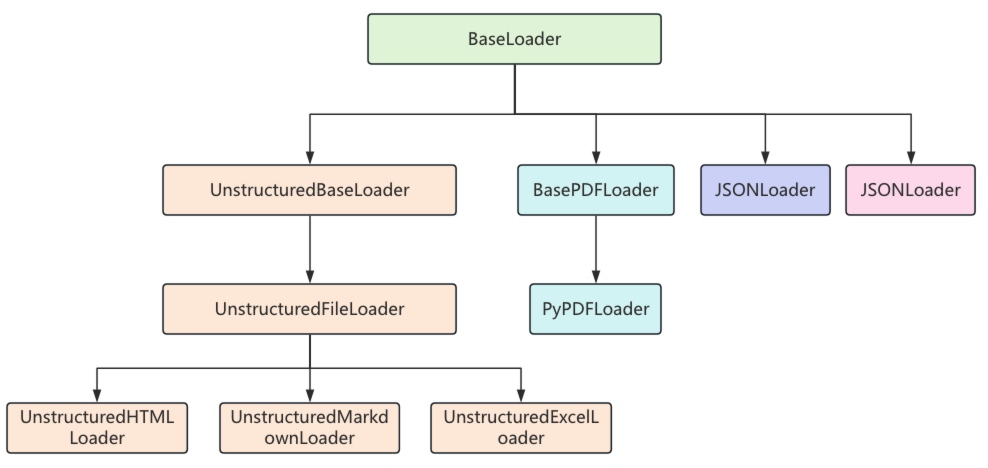
BaseLoader类中,定义了load()方法,用来加载文档对象,在方法内部又调用了lazy_load()懒加载方法
load( )
lazy_load()方法中,判断了子类是否重写了load()方法,如果重写了,则调用当前类的load()方法,如果没有重写则抛出异常,因此在子类中,要重写load()方法或lazy_load()方法
lazy_load( )
BaseLoader,并实现其中的load()方法,来编写自定义文档加载器的加载逻辑
2.2 Document文档类
文档加载器无论从什么来源进行文档加载,最终都是为了将文档信息解析为Document对象,下面一起来看看Document类中重要属性:
Document类中,主要包含两个重要属性:
page_content:表示文档的内容,类型是字符串
metadata :与文档本身无关的元数据信息。可以保存文档 ID、文件名等任意信息,类型是字典
2.3 文档加载器使用
下面以UnstructuredMarkdownLoader为例来介绍文档加载器的用法,使用UnstructuredMarkdownLoader读取md文件示例如下:
UnstructuredMarkdownLoader示例
UnstructuredMarkdownLoader把md文档内容加载成了一个Document对象,并且自动将文件名添加到了Document对象的元数据中
打印文档内容
mode="elements" 来将不同元素进行分离,解析成多个文档
UnstructuredMarkdownLoader示例
打印文档内容
2.4 自定义文档加载器
在实际开发中,基于文件的不同类型和不同格式,有时通过这些LangChain提供的文档加载器很难满足业务需求,例如需要根据特定规则提取文本片段,这时就需要开发自定义加载器,只需要定义一个自定义文档加载器类,并继承前面提到的BaseLoader类
假设有如下需求,对 faq.txt文件进行文档加载,内容如下,要求将问题和答案加载成一个文档,并添加文件创建日期元数据
自定义文档加载器
SimpleQALoader示例
使用示例
3. 文本分割器
3.1 LangChain 文本分割器
LangChain提供了多种文本分割器,常用的有:
大部分文本分割器都继承自
TextSplitter基类,该基类定义了分割文本的核心方法:
-
split_text():将文本字符串分割成字符串列表 -
split_documents():将Document对象列表分割成更小文本片段的Document对象列表 -
create_documents():通过字符串列表创建Document对象
3.2 递归文本分割器用法
RecursiveCharacterTextSplitter是LangChain中最常用的通用文本分割器,它会根据指定的字符优先级递归分割文本,直到所有片段长度不超过指定上限
首先介绍一下RecursiveCharacterTextSplitter构造函数几个核心参数:
chunk_size: 每个片段的最大字符数
chunk_overlap:片段之间的重叠字符数
length_function:计算长度函数
is_separator_regex: 分隔符是否为正则表达式
separators:自定义分隔符
3.3 分割文本
首先介绍使用split_text()方法进行文本分割,使用示例如下,其中RecursiveCharacterTextSplitter中指定的块大小为100,片段重叠字符数为30,计算长度的函数使用len()
RecursiveCharacterTextSplitter示例
将分割后的文本块转换为文档对象列表
3.4 分割文档对象
RecursiveCharacterTextSplitter不仅可以分割纯文本,还可以直接分割Document对象,使用示例如下:
RecursiveCharacterTextSplitter示例
输出分割后的文档信息
3.5 自定义分隔符
RecursiveCharacterTextSplitter默认按照["\n\n", "\n", " ", ""]的优先级进行分割,可以通过separators指定自定义分隔符
RecursiveCharacterTextSplitter示例
3.6 按标题分割Markdown文件
在对Markdown格式的文档进行分割时,一般不能像RecursiveCharacterTextSplitter默认分割规则方式进行分割,通常需要按照标题层次进行分割,LangChain提供了MarkdownHeaderTextSplitter类来实现这个功能
在对Markdown文件进行分割时,对于那些很长的文档,可以先利用MarkdownHeaderTextSplitter按标题分割,将分割后的文档再使用RecursiveCharacterTextSplitter进行分割,使用示例如下:
MarkdownHeaderTextSplitter示例
MarkdownHeaderTextSplitter将markdown文本内容分割成4个文档,之后在对每一个文档使用RecursiveCharacterTextSplitter进行分割,分割成了11个文档,并且在文档元数据中,还添加了文本片段所属的标题信息
执行结果如下
3.7 自定义文本分割器
当内置的的文本分割器无法满足业务需求时,可以继承TextSplitter类来实现自定义分割器,不过一般需要自定义文本分割器的情况非常少,
假设我们有如下需求,在对文本分割时,按段落进行分割,并且每个段落只提取第一句话,下面通过实现自定义文本分割器,来实现这个功能,示例如下:
CustomTextSplitter示例
文本分割
4. VectorStore存储组件
4.1 VectorStore组件介绍
对非结构化数据的存储与检索,最常用的方法是先将文本进行嵌入,转换为向量后存储到向量数据库中;在查询时,同样将查询文本嵌入生成向量,再将该向量传递给向量数据库,由数据库完成后续的相似度计算与检索过程 在 LangChain 中,这一过程由顶层接口 VectorStore 统一管理,不同类型的向量数据库只需实现该接口中的抽象方法即可完成集成。VectorStore 接口提供了多个常用方法,例如:-
add_texts:将文本列表转换为向量,并存储到向量数据库 -
add_documents:将文档列表转换为向量,并存储到向量数据库 -
as_retriever:返回向量数据库初始化的检索器 -
similarity_search_with_relevance_scores:进行相似性检索,返回文档及其相关性得分(范围在[0, 1]之间) -
delete:根据向量id删除向量数据 -
from_texts:传入文本列表、元数据信息、文本嵌入模型,返回创建好的VectorStore
VectorStore接口,常用的实现类如下:
4.2 RedisVectorStore数据存储
RedisVectorStore是 VectorStore 接口的一个实现类,下面将以它为例介绍 VectorStore 的用法。在使用 WeaviateVectorStore 之前,需要先安装langchain-redis 依赖:
RedisVectorStore数据存储
RedisVectorStore示例
打印前5个存储记录的ID
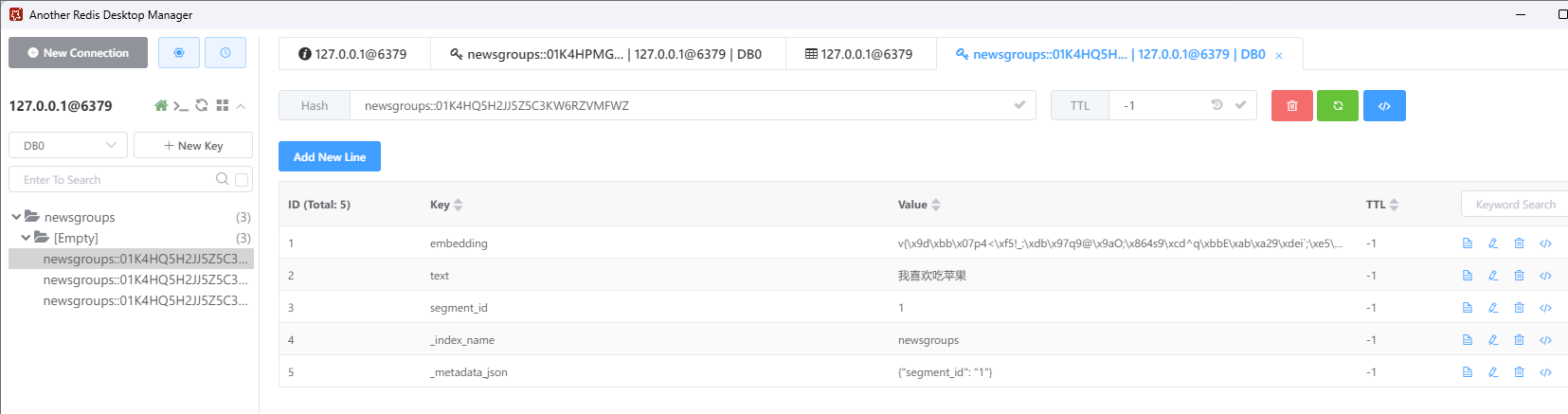
4.3 RedisVectorStore数据检索
在上面的示例程序中,我们将文本信息和元数据信息都保存到了数据库中。接下来,使用 VectorStore的similarity_search_with_relevance_scores() 方法进行相似性检索。在调用该方法时,传入查询文本 query,并指定 k=3,即返回匹配分数最高的三条数据(k 的默认值为 4)
similarity_search_with_relevance_scores示例
执行结果如下,返回了3个与查询文本最相关的文本信息
5. Retrievers检索器组件
5.1 BaseRetriever接口
BaseRetriever 是检索器相关类的顶层接口。当给定一个查询文本需要进行非结构化查询时,它比 VectorStore 更为通用。检索器本身不需要存储文档,只要能够对文档进行检索并返回检索到的文档即可。检索器可以通过 VectorStore 创建,也可以对诸如维基百科等数据源进行检索
在 langchain 项目中, VectorStore 是 底层存储接口,负责和具体的向量数据库交互(比如 Redis、Weaviate、Milvus、Pinecone 等) ,而 VectorStoreRetriever 是 LangChain 的 Retriever 抽象(Retriever 是统一的“检索器”接口,用于在链/Agent 中做检索)
最重要的是,BaseRetriever 是一个可运行组件,它可以方便地使用 LECL 表达式对检索器组件进行集成。检索器接受一个查询文本作为输入,返回一个 Document 对象列表作为输出。BaseRetriever 的 invoke 方法定义如下:
BaseRetriever.invoke示例
5.2 VectorStoreRetriever使用
在 RAG 应用中,当需要基于向量数据库进行文档检索时,就可以使用VectorStoreRetriever。它封装了向量数据库检索的底层逻辑,能够直接调用 VectorStore 的方法,从向量数据库中检索最相关的文档
在前面介绍 VectorStore 常用方法时,包括了 as_retriever() 方法,该方法可以构建一个检索器对象,这个检索器就是 VectorStoreRetriever
使用示例如下,使用as_retriever()方法创建了一个VectorStoreRetriever 对象,之后调用invoke()方法传入query进行文档检索
as_retriever示例
创建检索器,进行数据检索
MMR),可以在调用 as_retriever() 方法时通过 search_type="mmr" 指定,但前提是检索器所使用的底层数据库必须支持该检索方式
创建检索器,进行数据检索
search_type 之外,还可以使用 search_kwargs 将参数传递给 VectorStore 的底层搜索方法,例如传递 k 值,将默认匹配度最高的前三个文档返回(默认 k=4)
创建检索器,进行数据检索
5.3 MultiQueryRetriever使用
在向量检索过程中,查询文本会被转换为向量,并通过计算向量间距离来检索相似文档。然而,检索结果的准确性可能会受到查询文本表达方式的影响 因此,为了提升查询结果的准确性,可以将查询文本传递给大语言模型,由其生成多个不同表达方式的查询文本变体。随后,使用这些不同的查询文本分别进行文档检索,并将所有检索结果汇总、排序,返回最相关的文档MultiQueryRetriever(多查询检索器)正是实现上述 RAG 检索优化逻辑的工具。可以使用 MultiQueryRetriever.from_llm() 方法创建一个多查询检索器。进入 from_llm() 源码可以看到,除了需要传递检索器对象和模型对象之外,还可以传入 prompt 参数,该参数用于调用大模型生成多个查询文本的提示词,并提供了默认值
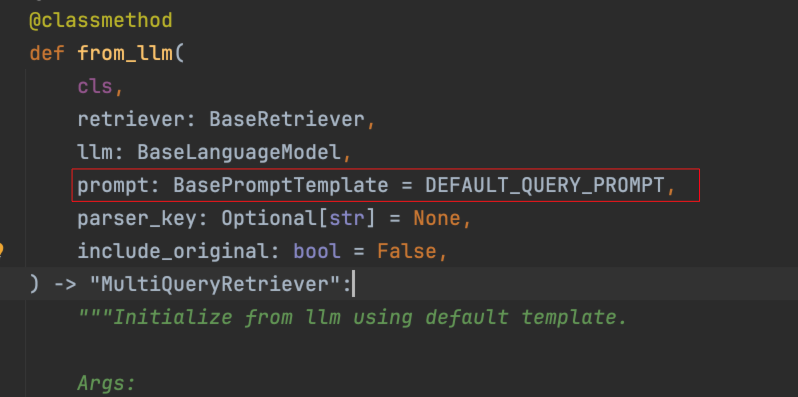
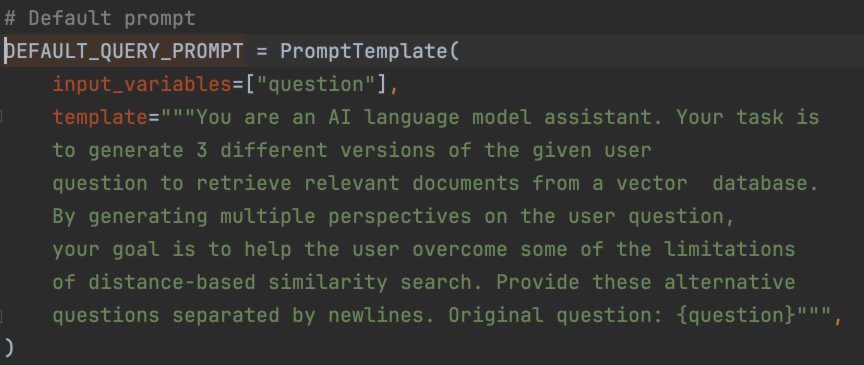
MultiQueryRetriever 使用示例如下,首先进行了日志设置,在调用大语言模型生成多个查询文本时,MultiQueryRetriever 会进行 INFO 级别的日志打印,将生成的文本输出,
在创建 MultiQueryRetriever 时,需要传入 BaseRetriever 对象、模型对象以及汉化后的 prompt,之后同样通过调用invoke()方法传入查询文本进行检索
MultiQueryRetriever使用
进行数据检索
5.4 自定义检索器实现
在前面已经介绍过BaseRetriever 接口,我们可以通过继承 BaseRetriever 来实现自定义检索器。查看 BaseRetriever 的 invoke 方法(省略部分代码)可以发现,最终真正执行检索的核心方法是 _get_relevant_documents
自定义检索器实现
_get_relevant_documents 是一个抽象方法,需要由子类去实现
自定义检索器实现
BaseRetriever 并实现 _get_relevant_documents 方法
假设有如下需求:需要一个自定义检索器,将传入的查询文本按空格拆分成关键词数组,并在文档中进行匹配。只要有任意一个关键词匹配成功,即返回该文档信息,同时支持通过传递参数控制检索器返回的文档数量
实现该需求的代码示例
输出检索结果,打印匹配文档的内容
6. RAG 实战项目
6.1 项目介绍
6.1.1 项目背景
随着美团业务的不断扩展,客服人员需要应对海量的用户咨询,包括订单问题、退款流程、配送异常、优惠政策等。传统的知识库客服系统依赖规则匹配,回答僵硬,难以及时覆盖最新的业务规则 为提升客户体验和客服效率,本项目基于 RAG(Retrieval-Augmented Generation,检索增强生成) 技术构建智能客服问答系统,将美团内部文档知识与大语言模型结合,实现更智能、更准确的自动化答复6.1.2 项目功能
针对智能客服系统本身,我们将采用RAG + LLM来完成这一需求。结合前面所学的知识,这个智能客服系统应该具备以下功能:- 支持历史记忆功能,并且能够实现历史记忆持久化
- 使用LCEL 表达式来构建链
- 支持RAG 检索功能,使大语言模型能够根据知识库文档内容进行作答
- 编写完善的提示词模板,内容包括历史对话信息、RAG 检索的上下文信息、用户提问,以及AI 作为客服的系统提示词
6.1.3 系统架构
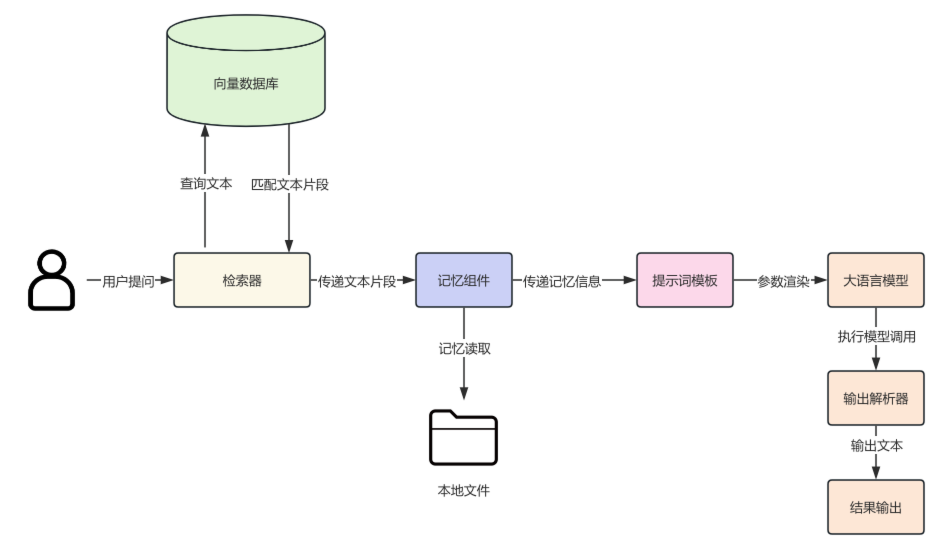
6.2 RAG 准备阶段
在 RAG 准备阶段,我们需要进行文档收集、文档处理、文档数据向量化操作以及文档相似性检索测试6.2.1 文档收集
收集美团客服相关知识文档,例如:- 业务手册(退款规则、订单处理流程)
- 常见问题 FAQ
- 内部客服知识库
- 实时更新的运营公告
安装依赖包
文档收集
原始文件内容
6.2.2 文档处理
我们已经爬取了 FAQ 文档,接下来就需要对收集到的文档进行统一处理,内容包括:- 文本清洗(去除 HTML 标签、无关字符)
- 分段切分(按规则或语义将文档拆分成小片段,便于检索)
- 元数据标注(来源、时间、业务类别等)
文档处理
执行结果如下
6.2.3 文档数据向量化
我们将 FAQ 数据格式化成 json 数据后,接下来就要转成向量数据并存储到向量数据库中,此处以 redis 为例,操作内容包括:- 使用 向量化模型(Embedding Model,如 BGE、OpenAI Embedding) 将文档片段转换为向量表示
- 存储至向量数据库(如 Milvus、Weaviate、Redis Vector、Faiss),支持高效的相似度搜索
文档数据向量化
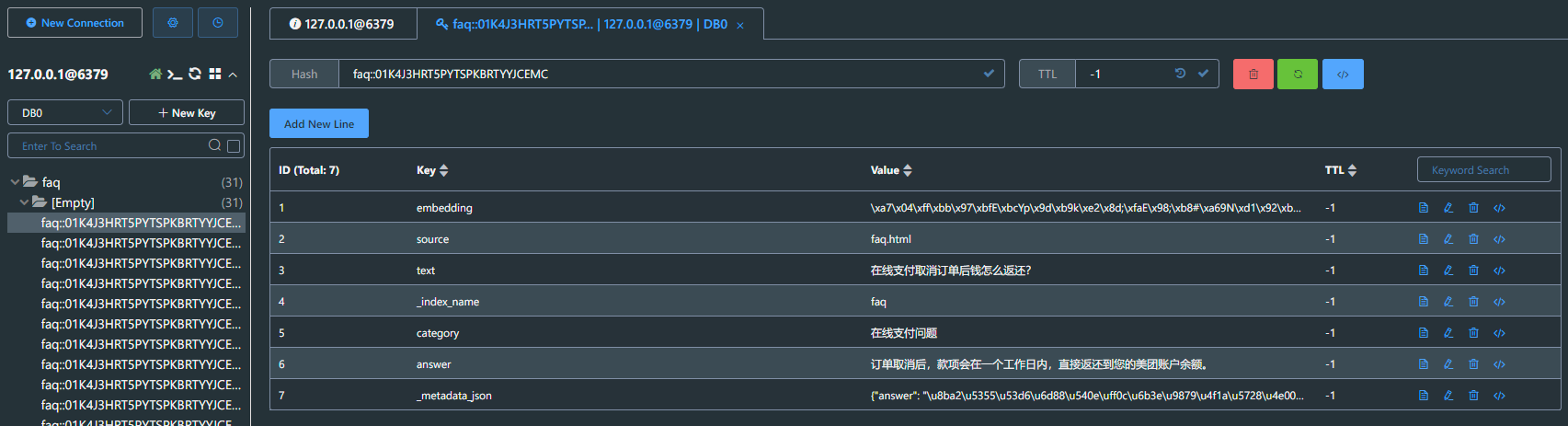
6.2.4 文档数据相似性检索
文档向量数据写入数据库后,接下来就是测试验证召回数据准确性,主要内容包括:- 用户提问后,将问题转换为向量,与向量数据库中的文档进行相似性匹配
- 召回与问题最相关的文档片段(如退款流程、配送延误规则),并返回给上层系统
文档数据相似性检索
文档数据相似性检索
6.2.5 构建提示词
- 把 用户问题 + 检索召回的上下文 拼接成一个高质量的 Prompt 送给大模型
- 提示词示例:
构建提示词
构建提示词
构建提示词
6.3 RAG 系统实现
6.3.1 主要步骤
接下来,开始实现智能客服系统,主要包含以下 8 个步骤:1
创建提示词模板
模板包括
系统消息、消息占位符、人类消息系统消息:设置 AI 的身份和当前业务场景消息占位符:传递聊天历史人类消息:传递用户提问以及通过 RAG 检索到的上下文信息
2
构建模型
使用
deepseek-r1:14b 模型3
创建输出解析器
创建一个
字符串输出解析器,用于结果输出4
构建检索器
连接
Weaviate 数据库,创建 WeaviateVectorStore 对象,并传入 文本嵌入对象、Weaviate 客户端对象、存储文本信息 key、集合名称然后调用 WeaviateVectorStore.as_retriever() 方法生成检索器,并指定只返回一条最相关的文档数据5
创建记忆组件
构建记忆组件,并将历史对话信息保存在
customer_service_history.txt 中6
构建链
构建 LCEL 链。链的后半部分较为直观,这里重点介绍前半部分由于检索器需要接收一个字符串参数,因此使用字典进行构建:将检索器的输出信息通过
format_documents() 方法拼接成字符串,作为 context 参数,同时添加 query 参数,供下一个可运行组件使用这里利用了 RunnableParallel 的参数传递功能。在 LCEL 表达式中,使用字典结构包裹并通过管道符连接时,会自动被包装成 RunnableParallel7
调用链
使用
stream() 方法调用链,传入用户提问stream() 可以实现流式输出,相比一次性返回结果,用户体验更好8
保存记忆
调用
save_context(),将对话记忆进行持久化6.3.2 代码编写
代码编写
执行结果如下